

This article presents the easiest way to turn your machine learning application from a simple Python program into a scalable pipeline that runs on a cluster.
Check out the Github repository for ready-to-use example code.
Overview
What you will learn:
- How to use luigi to manage tasks
- How to easily create Command Line Interface for python script with click
- How to run the pipeline in multiple Docker containers
- How to deploy a small cluster on your machine
- How to run your application on the cluster
Don’t calculate things twice – Luigify your pipeline
Some of the functions in your application may be time consuming and return huge outputs, so if your pipeline fails along the way, for any reason, it’s gonna cost you a lot of time and frustration to fix a small bug and rerun everything.
Let’s do something about it.
Suppose your pipeline needs to do the following things:
- fetch the data for the last 10 days;
- transform the data;
- make predictions with two different models.
You could code the workflow like this:
<p> CODE: https://gist.github.com/Haikane/a60f00c317f9b305997340ccd45c287f.js</p>
But this code is quite prone to errors, such as may occur while downloading the data – one network error, and all the work you’ve done is lost. Moreover, if you download data for the last ten days today and you’re planning to run the same pipeline again tomorrow, it doesn’t make much sense to download 90% of necessary data all over again.
So how can you avoid doing the same thing twice?
Sure, you can come up with ideas on how to save and reuse intermediate results, but there’s no need for you to code it yourself.
I recommend using the luigi package. It lets you easily divide your code into separate data-processing units – called tasks – each with concrete requirements and output.
One of your tasks could look like this:
<p> CODE: https://gist.github.com/Haikane/16ffa7c0cf01a1122fd136503f6c70c2.js</p>
From this snippet, we can see that:
- The name of the task is TransformData;
- The task has one parameter, namely date;
- It depends on ten tasks from the FetchData class, one for each of the ten previous days;
- It saves its output in a CSV file named after the ‘date’ parameter.
I’ve given a complete example of a dummy pipeline below. Take a moment to analyse how the tasks’ dependencies create a logical pipeline:
<p> CODE: https://gist.github.com/Haikane/81976f1c47bc22f6f54f5c3ba2a7518c.js</p>
Now, when you try to run the ‘MakePredictions’ task, Luigi will make sure all the upstream tasks run beforehand. Try installing Luigi with pip install luigi, save the above example in task-dummy.py, and run this command:
<p> CODE: https://gist.github.com/Haikane/027906319869c146cacbf0546bb961f7.js</p>
Furthermore, Luigi won’t run any task when its output is already present. Try running the same command again – Luigi will report that ‘MakePredictions’ for a given date has already been done.
Here you can find another good example that will help you get started with Luigi.
Parallelism for free – Luigi workers
Can I run multiple tasks at the same time?
Yes, you can! Luigi provides this functionality out of the box. Just by adding --workers 4 to the command, for example, you’re letting Luigi run four tasks simultaneously.
Let’s use this opportunity to present Luigi’s graphical interface.
Open a second terminal and run the following command:
<p> CODE: https://gist.github.com/Haikane/3c17347475a448efce669d66cc94d8c1.js</p>
This will start a so-called central Luigi scheduler that listens on a default port 8082. You can check its pretty dashboard on your browser at: http://localhost:8082.
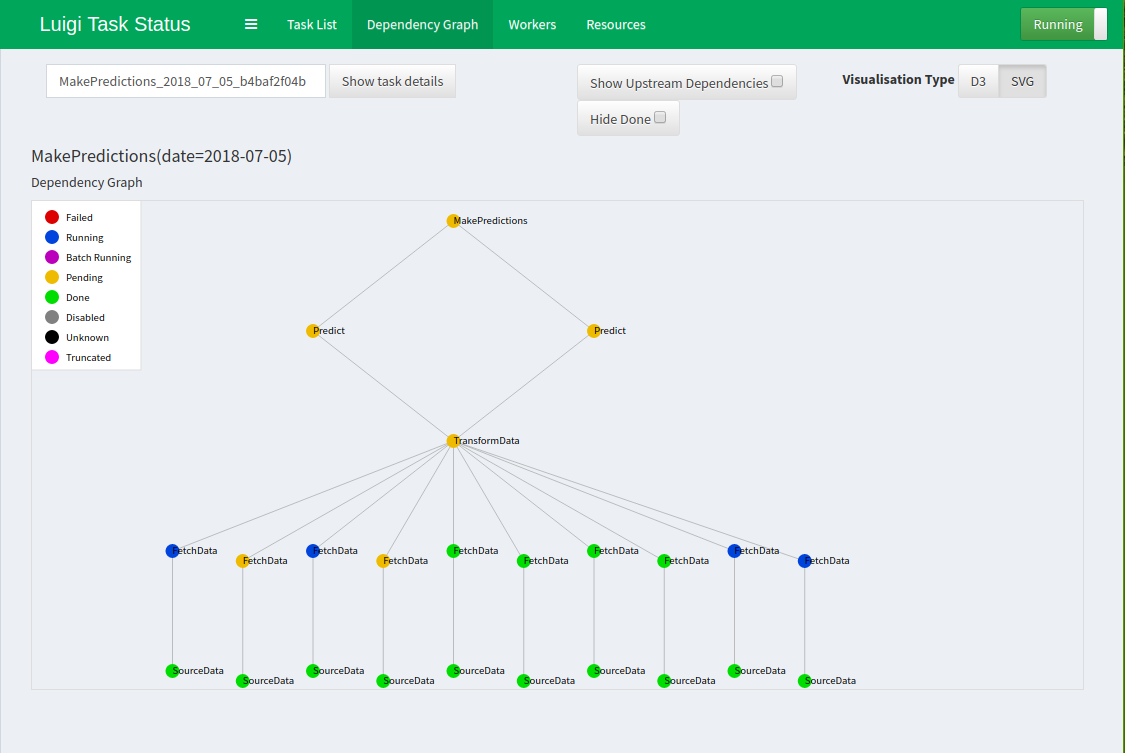
Now go back to the first terminal – you can run the Luigi command again, this time without the --local-scheduler argument (don’t forget to delete the files you’ve already created or choose another date if you want to see the tasks executing). If you want parallelism, add --workers 4 to the command. After refreshing the dashboard page, you should see a list of scheduled tasks. Click on the tree icon next to the MakePredictions task to see all its dependencies (Isn’t it pretty?):
Parallelism at scale – Moving to a cluster
Now we’re getting serious – if one machine is not enough for you to run your tasks in parallel, you can take your pipeline to the next level and deploy it on a cluster. I’ll walk you through all the necessary steps.
Share files between machines – Use AWS S3
In the previous example, all the files were saved locally on the same machine the tasks were executed on.
So how can I share files between multiple machines in the cluster?
There are many answers to this question, but we’ll focus on one of the possible ways – using Amazon’s S3.
AWS S3 is a Simple Storage Service. It lets you store your files in the cloud. Instead of /home/user/data/file.csv, you save your file under s3://bucket/data/file.csv. Python provides tools that make it easy to switch from local storage to S3.
Info: For this simplicity of this tutorial, if you want to follow the instructions below, I need you to set up a free AWS trial account you’ll use for storing your files. You can do it here and it’s completely free of charge for one year. You can opt out after this period if you don’t need it anymore.
After creating the account, go here and create a bucket. Think of a bucket as a partition on a hard drive.
To read and write data from S3, we’re gonna use luigi.contrib.s3.S3Target class. You can modify the dummy example by simply adding a proper import and replacing the LocalTarget in-task definitions as I’ve done here:
<p> CODE: https://gist.github.com/Haikane/d946a93c7e87f44a220bf43885fbfe0f.js</p>
You’ll also need to remove all self.output().makedirs() calls, because you don’t need to create folders on S3.
To use Luigi’s S3 functionality, you must pip install boto3.
You’ll also need to give your application credentials for S3 authentication. Let’s use the simplest approach: you can create a new Access Key on this site. You’ll get an Access Key ID and a Secret Access Key – save them in the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY, respectively.
Now your application should be able to read and write data to AWS S3. Try it out by running the pipeline again.
Containerize your pipeline to put it on a cluster
Sadly, you can’t put your Python code on a cluster and just execute it. However, you can run a certain command in a certain container.
I’ll show you how to refactor your pipeline to run each task in a separate Docker container.
Turn your tasks into mini programs – Add a simple CLI with Click
The first step towards running tasks in containers is making them runnable from the command line.
What’s the fastest way to write a CLI in Python?
Answer: Click. Click is an awesome package that makes creating command line interfaces very easy.
Let’s get back to the TransformData task example (not the dummy one). Its run() method calls two functions – namely, transform_data and save_result. Let’s say these functions are defined in the file called transform.py:
<p> CODE: https://gist.github.com/Haikane/204d07fe555e14e04f00204261af8f66.js</p>
Now let’s enable the running of these functions from the command line:
<p> CODE: https://gist.github.com/Haikane/8bbf056be35680c949f558615759ef0d.js</p>
Here, we defined a function (cli) that will be called when we run this script from a command line. We specified that the first argument will be an output path, and all further arguments will make up a tuple of input paths. After running ‘pip install click’, we can invoke data transformation from the command line:
<p> CODE: https://gist.github.com/Haikane/dfe7cb051c81d0936a0e05519060ad20.js</p>
For convenience, let’s call our project tac. If you add setup.py to your project and pip install it (take a look at example project to see how a project should be structured, and don’t forget to add __init__.py to the package directory), you should be able to run your script with:
<p> CODE: https://gist.github.com/Haikane/b342107273eea5d79663c80af5824cb7.js</p>
Make things portable – Run tasks in containers
Now the question is:
How can I easily create a Docker container in which to run my command?
Well, that’s simple.
First, create a requirements.txt file in the project root dir. You’ll need the following packages:
<p> CODE: https://gist.github.com/Haikane/d00397ffc68841c16652e365e130f960.js</p>
Now, create a Dockerfile in the project root dir and put this inside:
<p> CODE: https://gist.github.com/Haikane/2ef2c3aaf179508aca2c7ba6618a9e14.js</p>
Let’s break it down:
- FROM python gives us a base image with python installed.
- COPY requirements.txt /requirements.txt and RUN pip install -r /requirements.txt install all the required packages.
- COPY . /tac and RUN pip install /tac install our project.
- The last four lines will let us set AWS credentials inside the image on build time (it’s not a good practice, but let’s keep this tutorial simple).
Now you can build a Docker image containing your project by executing this from your project root dir (assuming you still have your AWS credentials in env variables):
<p> CODE: https://gist.github.com/Haikane/41f44bd718d26c39f04691b8a572ba33.js</p>
So you’ve just built a Docker image tagged tac-example:v1. Let’s see if it works:
<p> CODE: https://gist.github.com/Haikane/8a09b1aea0a6ced74790e4b4e66adee2.js</p>
This should save a docker-output.csv file in your S3 bucket.
Talk to the cluster – Prepare your tasks to be run in Kubernetes
If you want to run all – or just some – of your pipeline tasks in a cluster, Luigi comes with a solution.
Take a look at luigi.contrib.kubernetes.KubernetesJobTask.
Long story short, Kubernetes is a system that can manage a cluster. If you want to interact with a cluster, talk to Kubernetes.
To run a piece of code in a cluster, you need to provide the following information to Kubernetes:
- the image that should be used to create a container;
- the name that container should be given;
- the command that should be executed in the container.
Let’s modify our good old ‘TransformData’ task from the dummy pipeline to conform to these requirements.
- First, change the base class to ‘KubernetesJobTask’:
<p> CODE: https://gist.github.com/Haikane/c3f8d86d51bb9a539d6951c6226978d9.js</p>
- Give it a name:
<p> CODE: https://gist.github.com/Haikane/bc193184b752fdc24b328ee83dd44717.js</p>
- Define the command that should be run:
<p> CODE: https://gist.github.com/Haikane/d5d4bb995cd1b4f8768a8ca817ea6fa7.js</p>
- Provide the information to be passed on to Kubernetes:
<p> CODE: https://gist.github.com/Haikane/ee262137e682ad0e2837accbe54cbc9e.js</p>
- And delete the run() method, since this is implemented by KubernetesJobTask.
- Also, run pip install pykube, since it’s a requirement for KubernetesJobTask.
You should end up with something similar to what you can see in the example project.
But we can’t run it until we connect to a cluster. Keep reading.
Cluster at home – Kubernetes and Minikube
How can I run my pipeline in a cluster – without having access to a cluster?
The cool thing is, you actually can run a mini version of a real cluster on your laptop!
You can do this with Minikube. Minikube runs a single-node (single-machine) cluster inside a Virtual Machine on your computer.
Take a moment now to install Minikube. You can find instructions here. You’re gonna need all the components mentioned in these instructions.
After installation, you should be able to run
<p> CODE: https://gist.github.com/Haikane/f8d2b51ef719a90df8a50254ee5b223e.js</p>
to spin up your local cluster. Be patient, as this may take a while, especially when you do it for the first time. Verify that your cluster is running with
<p> CODE: https://gist.github.com/Haikane/586d4cd927048610c061b29510cbf27a.js</p>
You should see something similar to:
<p> CODE: https://gist.github.com/Haikane/c86df3cf7959dd6cdacae772de62d53c.js</p>
If everything is okay, you should be able to access Kubernetes’ dashboard, which shows the current status of your cluster:
<p> CODE: https://gist.github.com/Haikane/17cbfb383edc9006140f6f907f4860a4.js</p>
A new browser tab will open and show you this:
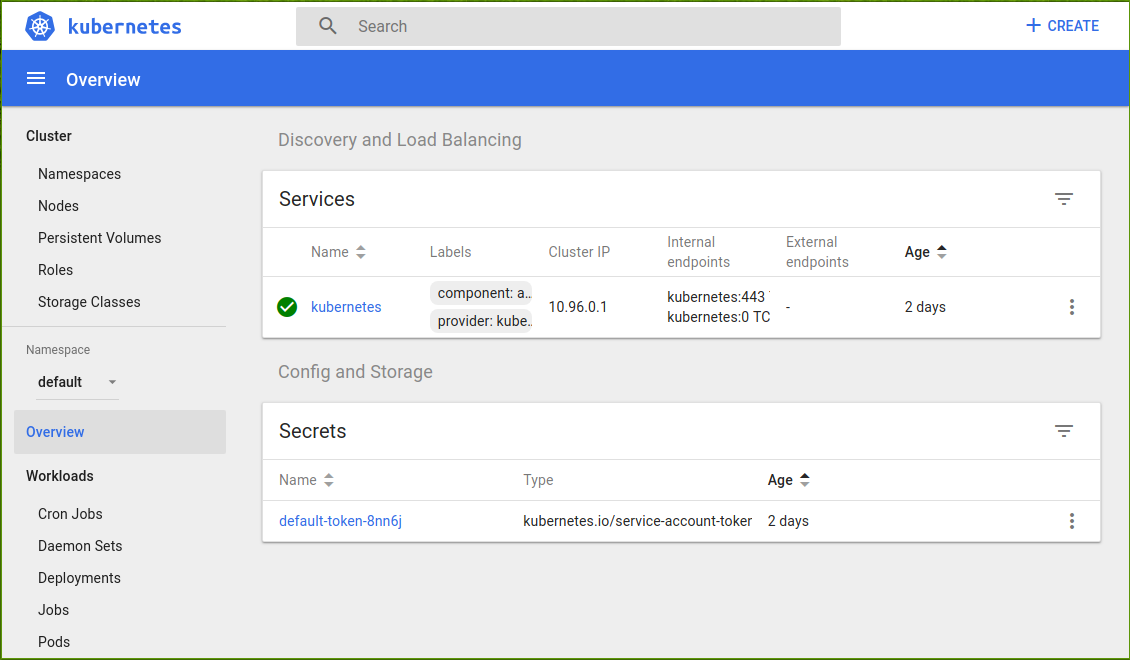
Since the cluster runs in a separate (virtual) machine, it doesn’t have access to your Docker image (since you haven’t pushed it to any online registry). We’ll use a little trick to overcome this.
The following command will set your current console session to execute docker commands using not your local Docker Engine, but the cluster VM’s Docker Engine:
<p> CODE: https://gist.github.com/Haikane/8b70023a3d6b7f110af216a354dff2ee.js</p>
Now all you need to do is call the ‘docker build’ command again. This time, your image will be built inside the VM:
<p> CODE: https://gist.github.com/Haikane/ce3cf659f8041eae24031fdf349f8d30.js</p>
And here comes the moment of truth.
We’re gonna execute our pipeline inside the cluster we’ve just configured.
If everything went well, just calling the Luigi command should be enough. Minikube has already set the proper configuration, so KubernetesJobTask knows where the target Kubernetes is running.
So try executing this command from the directory where task-dummy lives:
<p> CODE: https://gist.github.com/Haikane/2c03a27c486355cea8fb99fd50cdce7b.js</p>
and watch how your TransformTask job runs in the cluster:

Endnotes
- If KubernetesJobTask reports a message like this: No pod scheduled by transform-data-20180716075521-bc4f349a74f44ddf and fails to run, it’s probably a bug, and not your fault. Check the dashboard to see if the transform-data-... pod has the status Terminated:Completed. If so, then the task is actually finished and running your pipeline again should solve the problem. It’s probably Minikube’s fault.
- Consider Google Kubernetes Engine for spinning up a real cluster.
- When using Google’s cluster, consider switching from AWS S3 to Google Cloud Storage to significantly speed up data access. This module should be helpful.
- Read more about speeding up your pipeline with Dask and integrating it with Kubernetes.